
阴影图(Shadow Map)算法原本是用于计算阴影的算法,也是现在使用最为广泛的阴影计算方法。由于我自己研究生期间的研究领域是计算机图形学中的3D模型与实时视频的虚实融合,其核心算法就是Shadow Map。
有必要先说明一下什么是虚实融合。开头放张图好像比较符合江湖规矩…

上图就是3D模型与实时视频虚实融合的最终效果gif。所谓的虚实融合就是虚拟的3D模型数据(对现实场景建模得来)和现实的视频(与模型数据相同地点的摄像头视频数据)融合。
数据准备
- 3D模型数据。如下图。

- 摄像头的标定参数(为了得到摄像头的视图矩阵和透视投影矩阵)。
- 摄像头的视频。

虚实融合的核心原理解释
即Shadow Map如何实现虚实融合。
简单来说,虚实融合就是要把摄像头的视频逐帧贴到对应的3D模型上。这个贴的过程,就是用Shadow Map做到的。这里有必要先回顾一下Shadow Map应用在阴影中的基本原理。
Shadow Map计算阴影的基本原理
Shadow Map算法计算阴影的基本原理是:从光源可以看到场景中所有的被光照亮的表面。所有的隐藏(不可见)元素都处于阴影区域。
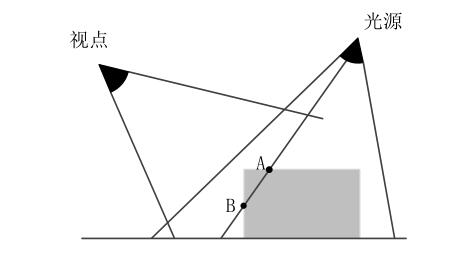
为了判断表面是否对于光源是可见的,需要分三步:
- 从光源的位置对场景进行渲染,得到一张深度图p1。其中的每一个元素都记录了第一个可见表面的深度值(与光源的距离)。
- 从真实的视点对场景进行渲染,得到一张深度图p2。
- 对深度图p2逐片元(如上图中的B)地通过矩阵变换,切换到光源空间下,与深度图p1相应位置(如上图中的A)的深度进行比较。如果大于p1相应位置的深度(距离光源更远),那么说明p2上的此片元(如上图中的B)应该是阴影。否则,被照亮。
Shadow Map在虚实融合中的应用原理
在虚实融合中,Shadow Map的第三步是反过来的。
基本原理:
- 从摄像头(替换上述的光源)的位置对场景进行渲染,得到一张深度图p1。
- 从真实的视点对场景进行渲染,得到一张深度图p2。
- 对深度图p2逐片元(如上图中的B)地通过矩阵变换,切换到摄像头空间下,与深度图p1相应位置(如上图中的A)的深度进行比较。如果小于p1相应位置的深度(距离摄像头更近),那么说明p2上的此片元(如上图中的B)能够被摄像头覆盖到,即替换为摄像头视频纹理。否则,就覆盖不到,不替换,维持原状。
就这样进行逐帧逐像素的计算,从而得到了开头的那个虚实融合的gif图。这是场景中只有一个摄像头的时候,如果场景中出现多个摄像头,采用的技术会有点不一样,改天再写一篇说说吧。




